Hypothesis Testing - an Overview
Based on the “Statistical Consulting Cheatsheet” by Prof. Kris Sankaran
Many problems in consulting can be treated as elementary testing problems. First, let’s review some of the philosophy of hypothesis testing. Testing provides a principled framework for filtering away implausible scientific claims. It’s a mathematical formalization of Karl Popper’s philosophy of falsification. The underlying principle is simple: “ Reject the null hypothesis if the data are not consistent with it, where the strength of the discrepancy is formally quantified through the notion of p-value”.
The Objective: Measuring the strength of discrepancy by computing a p-value
Consequently, one of the main goals of hypothesis testing is to compute a p-value. A p-value can be defined as “the probability of observing an event as extreme as what I am observing under the null”, where the null is the default, “chance” scenario.
Example: For instance, suppose that I want to assess if Soda A is better than Soda B. I could do a survey, and ask people to give a score to each of the soda, and average my results. Suppose there is no difference between the two: the difference between the two averages is a random variable, centered at 0. Conversely, if there is a true underlying difference (let’s call it \(\delta\)), then the difference between my two averages: \(\Delta = \bar{X}_a -\bar{X}_b\) is also a random variable, but centered at \(\delta\). The entire point of hypothesis testing becomes to quantify how extreme this difference \(\Delta\) has to be to “reject the null” — i.e, to say that it is unlikely for \(\Delta\) to be this extreme if the null (“there is no difference in sodas”) is true.This is the concept at the core of p-values: a p-value of 0.04 means that, just by chance, only 4% of events would have seen a difference this big. If I am willing to accept that 4% is too small (statisticians usually abide by the convention that anything less than 5% chance is unlikely to happen by chance alone), I can reject the null.
A small p-value, typically < 0.05, indicates strong evidence against the null hypothesis; in this case you can reject the null hypothesis. On the other hand, a large p-value, > 0.05, indicates weak evidence against the null hypothesis; in this case, you do NOT reject the null hypothesis. The value 0.05 is the threshold usually employed by the community — you can think of it as a scientific convention for determining significance.
Importantly, the p-value is the probability of observing events as extreme as my observations under the null, but not the probability that the hypothesis is correct!
\[p_{value} = \mathbb{P}[\text{observations} \; \mid \; \text{hypothesis } H_0 ] \ne P[ \text{hypothesis } H_0 \; \mid \; \text{observations} ]\]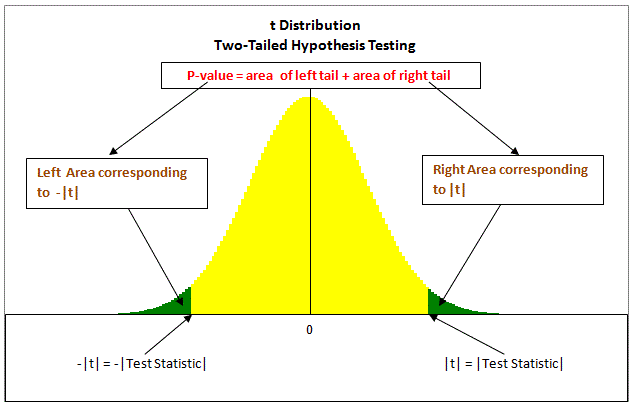
P-values should NOT be used a “ranking”/“scoring” system for your hypotheses.
The Recipe
Of course, to determine what this p-value is, there are three essential steps:
- Step 1: Defining the Null and Alternate Hypotheses __The null hypothesis (\(H_0\)) is a statement assumed to be true unless it can be shown to be incorrect beyond a reasonable doubt. This is something one usually attempts to disprove or discredit. The alternate hypothesis (\(H_1\)) is a claim that is contradictory to \(H_0\) and what we conclude when we reject \(H_0\).
- Step 2: Defining a test statistics that is, what I will be measuring (eg, the average score). This has to be tailored to the problem that I am really interested in.
- Step 3: Defining what the null looks and behaves like: this is what will allow me to measure whether or not what I am observing in my own dataset is extreme or not.
While testing is fundamental to much of science, and to a lot of our work as consultants, there are some limitations we should always keep in mind:
-
The different types of errors: There are two kinds of errors we can make: (1) Accidentally falsify when true (false positive / type I error) and (2) fail to falsify when actually false (false negative / type II error). Different types of tests will allow to control for these errors, and finding the right hypothesis test thus becomes a matter of finding the test that is “the most sensitive” to the data that you are measuring.
- The problem of defining “the null”: In order to build a test, we need to be able to articulate the sampling behavior of the system
under the null hypothesis.
- Often, describing the null can be complicated by particular structure present within a problem (e.g., the need to control for values of other variables). This motivates inference through modeling, which is reviewed in the inference in linear model section of this website.
- We need to be able to quantitatively measure discrepancies from the null. Ideally we would be able to measure these discrepancies in a way that makes as few errors as possible. This is in fact the motivation behind optimality theory: how can I run my experiments in a way that allows the “purest” measures for the question that I would like to answer?
- Practical significance is not the same as statistical significance. A p-value should never be the final goal of a statistical analysis. They should be used to complement figures / confidence intervals / follow-up analysis that provide a sense of the effect size.
The Ingredients
To find the right hypothesis test, we need to select the right “ingredients”. That requires to answer a minimum of four questions:
- Question 1: What type of data do I have?
- Categorical Data Contingency Tables
- Continuous Data: t-tests, Anova
- Question 2: Can I assume my data points are independent?
- Are there some paired variables?
- Is my data stratified into clusters?
- Are there some potential batch effects?
- Question 3: Am I testing a single, or multiple hypotheses at the same time?
- If there are multiple hypotheses, then you will need to correct for multiple hypothesis testing.
- Question 4: How many datapoints do I have?
- This will help you determine whether or not you will need a non-parametric hypothesis test.
Prospective Measurements: Finally, if you haven’t done your measurements yet and you’re looking to assess how many samples you would need to answer your question, do look at our page on power analysis.